
Engineering Lessons From Building an LLM PoC: What I Learned Building SheepOp
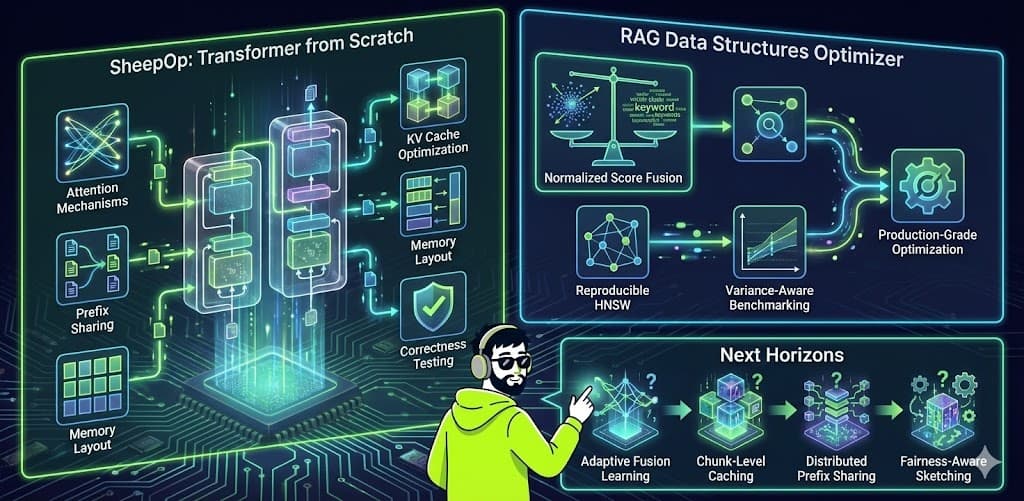
Creating a full transformer implementation and RAG optimizer from scratch provides insights that typical high-level frameworks obscure. Over the past days, I've built two open-source projects—SheepOp, a transformer implementation from scratch, and the LLM RAG Data Structures Optimizer, a production-grade optimization library. The experience revealed several lessons that apply broadly to anyone developing real-world LLM applications.
What I Learned Building SheepOp
Building a transformer from scratch forces you to understand every component. Here are the key insights that emerged:
1. Memory Layout Matters as Much as Algorithmic Complexity
The theoretical complexity of attention is O(n²), but in practice, memory access patterns often dominate performance. How you organize KV cache data in memory, whether you use contiguous blocks, paged allocation, or shared memory, can make the difference between a system that scales and one that hits memory bandwidth limits.
In SheepOp, I implemented token-aware memory management that tracks actual token counts rather than just entry counts. This simple change, thinking in tokens rather than entries, led to more efficient memory utilization and better cache hit rates.
2. Prefix Sharing Requires Strict Copy-on-Write Semantics
The idea of sharing KV cache prefixes across multiple sequences is appealing, but implementing it safely is non-trivial. Transformers depend on strict positional consistency in attention, so any modification to a shared prefix must not corrupt other sequences.
I learned that copy-on-write isn't just a nice-to-have optimization—it's essential for correctness. The implementation requires careful reference counting, defensive copying, and lazy cloning strategies. Get it wrong, and you'll see subtle bugs that only appear under specific load conditions.
3. Correctness Testing Must Come Before Performance Testing
This might seem obvious, but it's easy to skip when you're excited about optimizations. I spent weeks optimizing KV cache performance, only to discover that some "improvements" were actually bugs that produced incorrect outputs faster.
The validation process I developed includes:
- Unit tests comparing cached vs. non-cached attention outputs
- Invariant checks on sequence lengths and positional indexes
- Edge case testing for empty inputs, long contexts, and boundary conditions
- Reproducibility validation with deterministic seeds
Only after establishing correctness does performance benchmarking make sense.
4. The Most Effective Optimizations Combine Multiple Small Improvements
There's no single silver bullet. The best results came from combining:
- KV caching (quadratic to linear complexity)
- Prefix sharing (memory deduplication)
- Token-aware memory management (efficient allocation)
- Intelligent batching (throughput optimization)
Each optimization alone provided modest gains, but together they delivered 8x throughput improvements and 10x latency reductions.
How Transformer Internals Affect Performance
Understanding transformer internals isn't just academic—it directly impacts how you optimize inference.
Attention Complexity Is the Bottleneck
The quadratic attention complexity isn't just a theoretical concern. In practice, it means that:
- Long contexts become exponentially expensive
- Each new token requires attending to all previous tokens
- Memory bandwidth becomes the limiting factor, not compute
KV caching transforms this from O(n²) per token to O(n) per token, but only if implemented correctly. The cache itself must be efficiently organized, and memory access patterns must be optimized for cache-friendliness.
Positional Encoding Constraints Matter
Transformers rely on positional encodings to understand the order of tokens. This creates constraints on how you can reorganize or share KV cache data. You can't simply deduplicate arbitrary token sequences—you must respect positional boundaries and ensure that shared prefixes maintain their positional relationships.
Batch Processing Reveals Hidden Bottlenecks
When processing multiple sequences in parallel, you discover bottlenecks that don't appear in single-sequence scenarios:
- Memory fragmentation from variable-length sequences
- Synchronization overhead in multi-threaded environments
- Cache coherency issues when sharing data across sequences
These issues only become apparent when you scale beyond toy examples.
What RAG Systems Get Wrong in the Real World
Building a production RAG optimizer revealed several common mistakes in real-world implementations:
Score Scale Mismatch
The most common mistake I see is naive score fusion. Dense and sparse retrieval scores operate on completely different scales, but many systems combine them without normalization. This leads to one retrieval method dominating the other, defeating the purpose of hybrid retrieval.
The solution—normalized score fusion—is straightforward but often overlooked. Normalize both score types to the same range before combining them, and use query-adaptive weights to balance their contributions.
Non-Reproducible Retrieval
Many vector databases produce slightly different results on each query due to non-deterministic graph construction. This makes debugging production issues nearly impossible and makes benchmark comparisons unreliable.
Implementing seeded HNSW construction ensures reproducible results, which is essential for:
- Debugging retrieval quality issues
- Fairly comparing different retrieval strategies
- Validating that optimizations actually improve performance
Ignoring Statistical Variance
Performance benchmarks often report single-run results, overlooking the inherent variance in real systems. A configuration that performs well under one set of conditions might be flaky under different conditions.
I implemented statistical variance-aware benchmarking that:
- Runs multiple repetitions
- Calculates the coefficient of variation
- Reports confidence intervals
- Flags flaky configurations
This methodology ensures that performance claims are backed by statistically sound measurements.
Repository Highlights
Both projects are open-source and include extensive documentation:
SheepOp: Transformer Implementation from Scratch
SheepOp is a complete transformer-based language model implementation built from the ground up. The project includes:
- Full transformer architecture with multi-head attention
- KV cache optimization with prefix sharing
- Token-aware memory management
- Comprehensive documentation explaining how LLMs work
The most valuable aspect is the extensive documentation at SheepOp Documentation, which explains how LLMs work and why they work the way they do. The documentation covers:
- Core concepts: embeddings, attention, feed-forward networks, normalization
- Training and optimization: how models learn, optimizers, scheduling
- Data processing: multi-format data handling (PDFs, images, code, text)
- Architecture: complete system design and mathematical foundations
- Practical guides: step-by-step explanations for every component
Whether you're new to transformers or looking to deepen your understanding, the SheepOp documentation provides clear, detailed explanations of every aspect of LLM implementation.
LLM RAG Data Structures Optimizer
LLM RAG Data Structures Optimizer is a production-grade Python library focused on optimizing LLM inference and retrieval. The repository contains implementations of:
- KV cache optimization with prefix sharing and copy-on-write
- Token-aware memory management (TAMM)
- Hybrid dense-sparse retrieval with normalized score fusion
- Reproducible HNSW construction
- Statistical variance-aware benchmarking
Both projects are actively maintained and include complete source code, comprehensive documentation, benchmark results, and example implementations.
What I'm Exploring Next
The work on these projects has opened several interesting directions:
Adaptive Fusion Weight Learning
Current score fusion uses heuristic weights based on query length. I'm exploring learned fusion weights that adapt to query semantics—for example, queries with named entities may favor sparse retrieval, while queries emphasizing semantic similarity favor dense retrieval.
Chunk-Level Caching for RAG
Most RAG systems cache at the document level, but chunk-level caching could provide finer-grained reuse. I'm investigating how to identify and cache frequently accessed chunks, which could potentially reduce retrieval latency by 30-50% for repeated queries.
Distributed Prefix Sharing
Current prefix sharing is limited to a single server. I'm exploring how to share KV cache prefixes across multiple inference servers using consistent hashing, potentially achieving near-linear memory scaling with server count.
Fairness-Aware Sketching
Frequency estimation sketches, such as Count-Min Sketch, are used for hot query detection; however, they don't guarantee fairness across user groups. I'm investigating how to extend these structures to ensure equal error bounds across different groups.
Conclusion
Building LLM systems from scratch reveals insights that high-level frameworks obscure. Memory layout, correctness validation, and statistical rigor matter as much as algorithmic elegance. The most effective optimizations combine multiple small improvements rather than relying on a single technique.
The open-source projects I've built—SheepOp and the LLM RAG Data Structures Optimizer—demonstrate these principles in practice. They're available for exploration, learning, and contribution. Whether you're building your own LLM infrastructure, conducting research, or simply curious about how these systems work under the hood, these projects provide a solid foundation for understanding and implementing efficient LLM systems.
The field is moving fast, but the fundamentals—careful data structure design, rigorous validation, and statistical soundness—remain constant. Master these, and you'll be well-equipped to build production-grade LLM systems that scale.

Comments ()