
KV Caching, Prefix Sharing, and Memory Layouts: The Data Structures Behind Fast LLM Inference

Large Language Models (LLMs) have reshaped how we build applications, but behind the scenes, their performance depends heavily on the data structures and algorithms that support them. While pre-training and fine-tuning often receive the spotlight, the real engineering challenge emerges in production systems: delivering fast, cost-efficient inference at scale.
I walk through the core data structures that make LLM inference efficient. Drawing from my open-source implementation work, I explain how KV caching, prefix sharing, copy-on-write semantics, and intelligent memory management come together to transform inference from a quadratic to a linear operation. The goal is to provide readers with a clear, practical understanding that they can apply immediately when designing their own LLM infrastructure.
This post summarizes the lessons learned while building SheepOp, a proof-of-concept transformer implementation that demonstrates these optimizations in practice.
Why LLM Performance Is a Data Structure Problem
At a high level, every LLM relies on the Transformer architecture. Its attention mechanism drives model quality, but it also introduces a fundamental computational bottleneck: each new token must attend to every previous token. This creates a quadratic cost that grows with input length, ultimately making long-context inference expensive and slow.
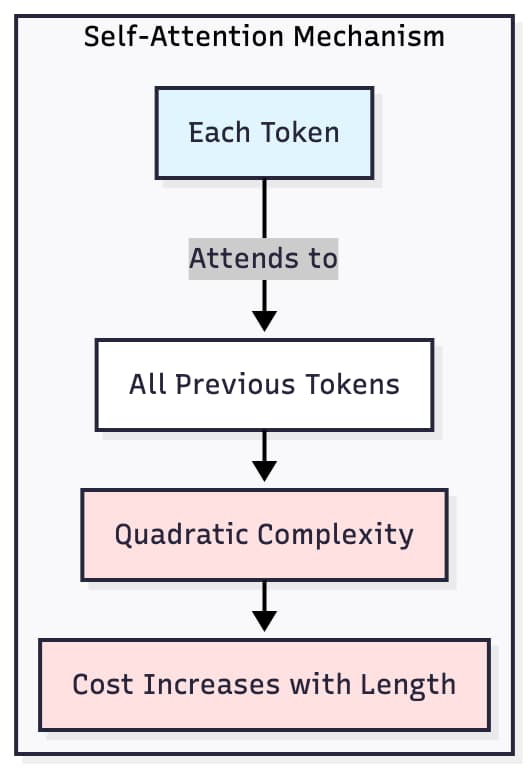
The typical solution is to use a Key-Value (KV) cache. During generation, the model stores the key and value tensors for previously processed tokens. On subsequent forward passes, the model reuses these cached representations rather than recomputing them. KV caching transforms inference from a quadratic to a linear operation per new token, enabling real-time generation.

However, the KV cache is itself a data structure, and its performance depends on how intelligently it is implemented. Memory fragmentation, redundant copies, and inefficient indexing can quickly erode any theoretical speedups. This is where design matters.
Rethinking the KV Cache: Prefix Sharing and Copy-on-Write
Most LLM serving systems treat each request as an independent sequence. Even when multiple users generate text from the same prompt, their KV data structures are duplicated in GPU memory. This leads to unnecessary memory usage and reduced throughput.
Prefix sharing changes that.
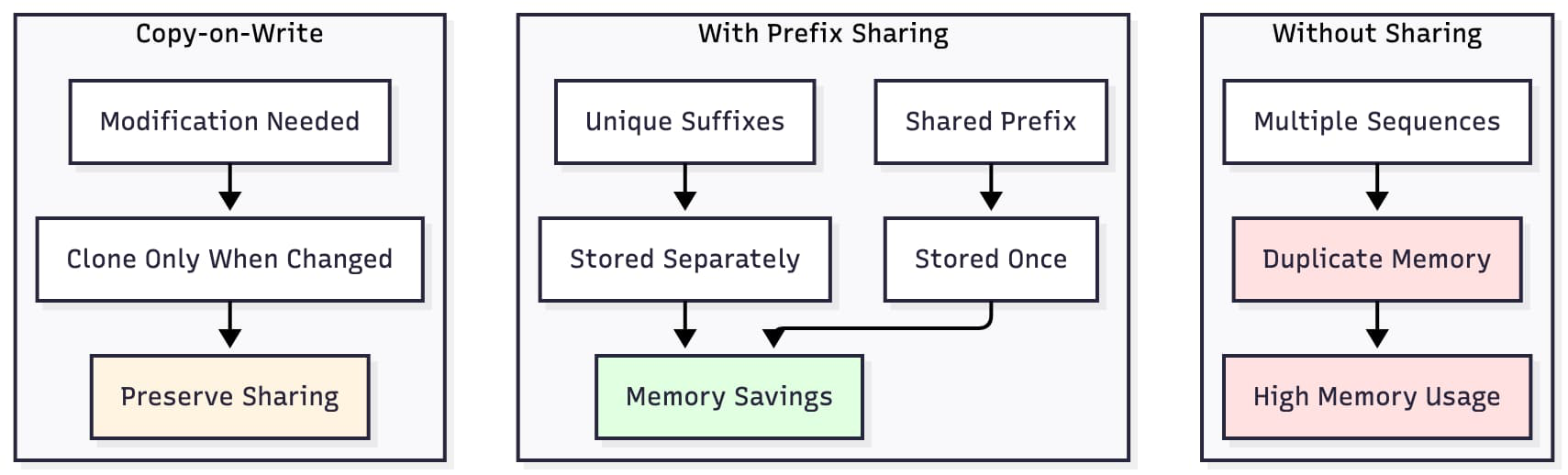
By recognizing that many sequences begin with the same prompt or system message, we can store the shared KV prefix once and let multiple decoding streams reference it. Each request only stores the unique suffix it generates. This significantly reduces memory consumption and increases batch throughput, particularly in multi-user environments like chatbots.
The challenge is correctness. Because transformers depend on strict positional consistency in attention, the system must ensure that any modifications to the shared prefix do not corrupt other sequences. To solve this, we use a copy-on-write (COW) approach. When a new request needs to modify or extend a shared prefix, the system clones only the affected portion, leaving the rest intact.
This architecture mirrors the principles used in operating systems and high-performance inference engines such as vLLM. In practice, it results in lower GPU memory usage, fewer kernel launches, and faster decoding.
Token-Aware Memory Management: Allocating KV Regions Intelligently
While prefix sharing resolves duplication, efficient KV caching still requires careful memory layout. The goal is to map token streams to memory in a way that minimizes waste and maximizes reuse.
Token-Aware Memory Management (TAMM) provides a practical solution. Instead of preallocating fixed-size blocks, TAMM assigns memory based on expected sequence length, attention requirements, and cache hit behavior. This avoids fragmentation and reduces over-allocation, especially for variable-length inputs.
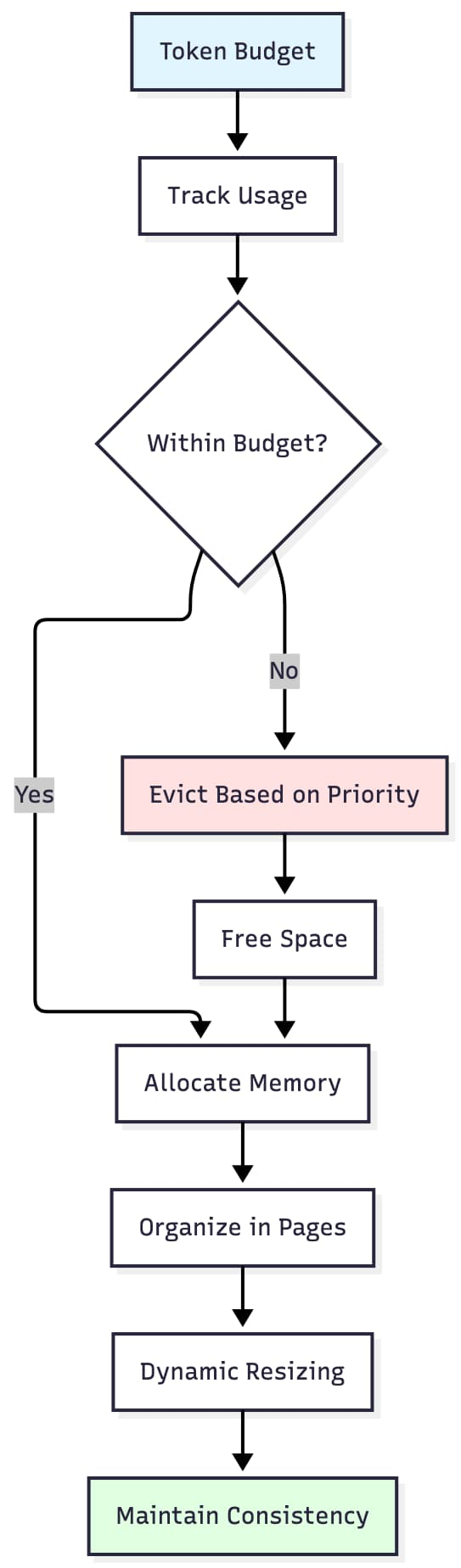
In the SheepOp prototype, I implemented this concept by:
- tracking token counts across batch operations
- automatically resizing KV buffers
- preserving cache invariants during sequence extension
- ensuring compatibility with positional encoding constraints
This mirrors challenges encountered in production systems and is essential for stable long-context inference.
Evaluating Performance: Correctness Before Speed
One of the most overlooked aspects of LLM optimization is validation. Many performance measurements are misleading because they fail to account for warm-up costs, GPU kernel variation, or caching artifacts. Before benchmarking throughput and latency, the system must first establish correctness.
In my work, I found that validating KV cache behavior required:
- unit tests for attention outputs using and not using the cache
- strict invariants on sequence lengths and positional indexes
- tests for empty inputs, long contexts, and out-of-bound memory
- deterministic seed control for reproducible results
Only once correctness is reliable does performance analysis make sense. This prevents the common pitfall of "optimizing into a bug," where supposed speedups come from incorrect model behavior rather than real efficiency gains.
Performance Results: Real-World Impact
The following benchmarks demonstrate the practical impact of KV cache optimizations in the SheepOp prototype:
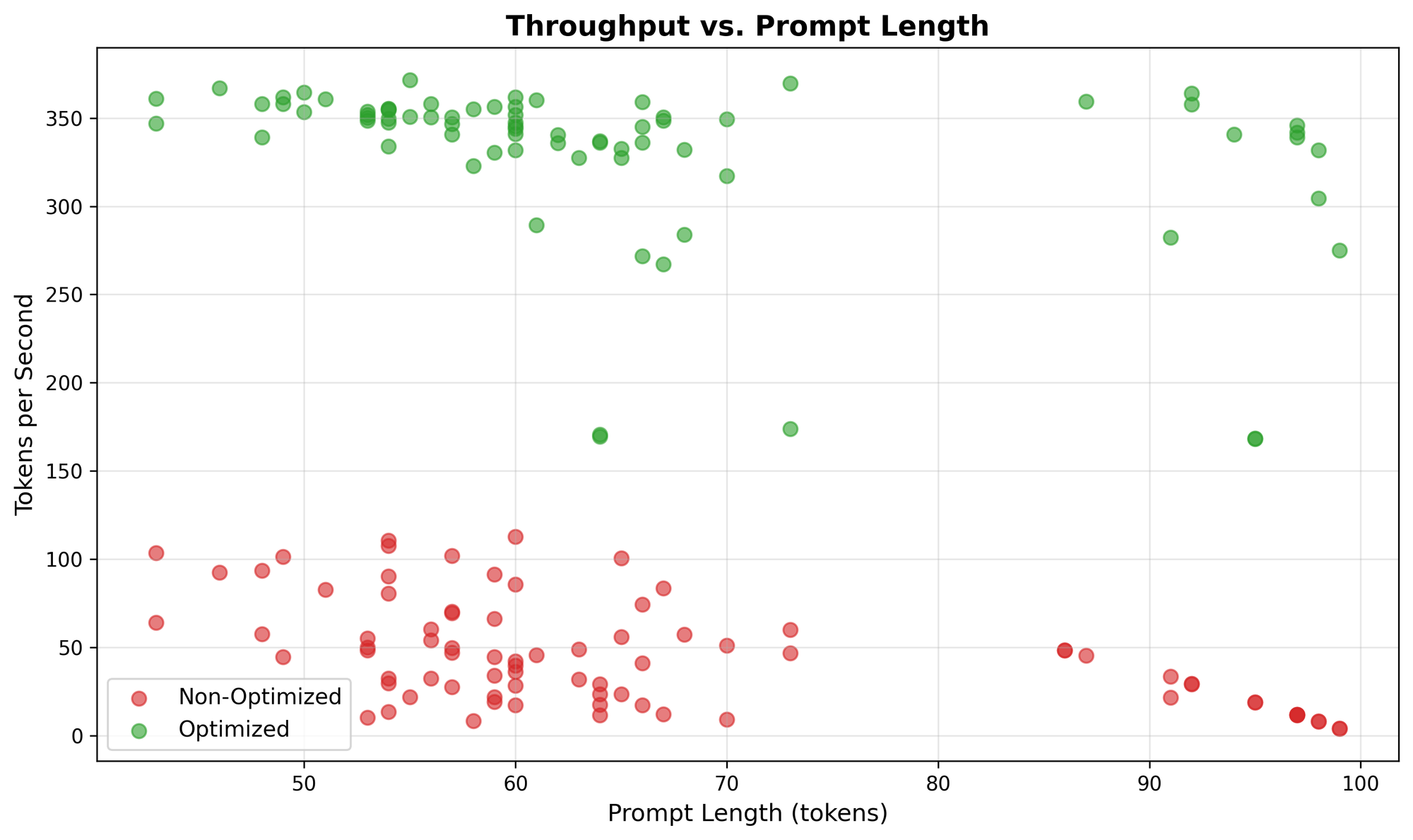
Throughput scaling: optimized system maintains high throughput (~320-370 tokens/second) across all prompt lengths, while non-optimized performance degrades significantly for longer prompts.
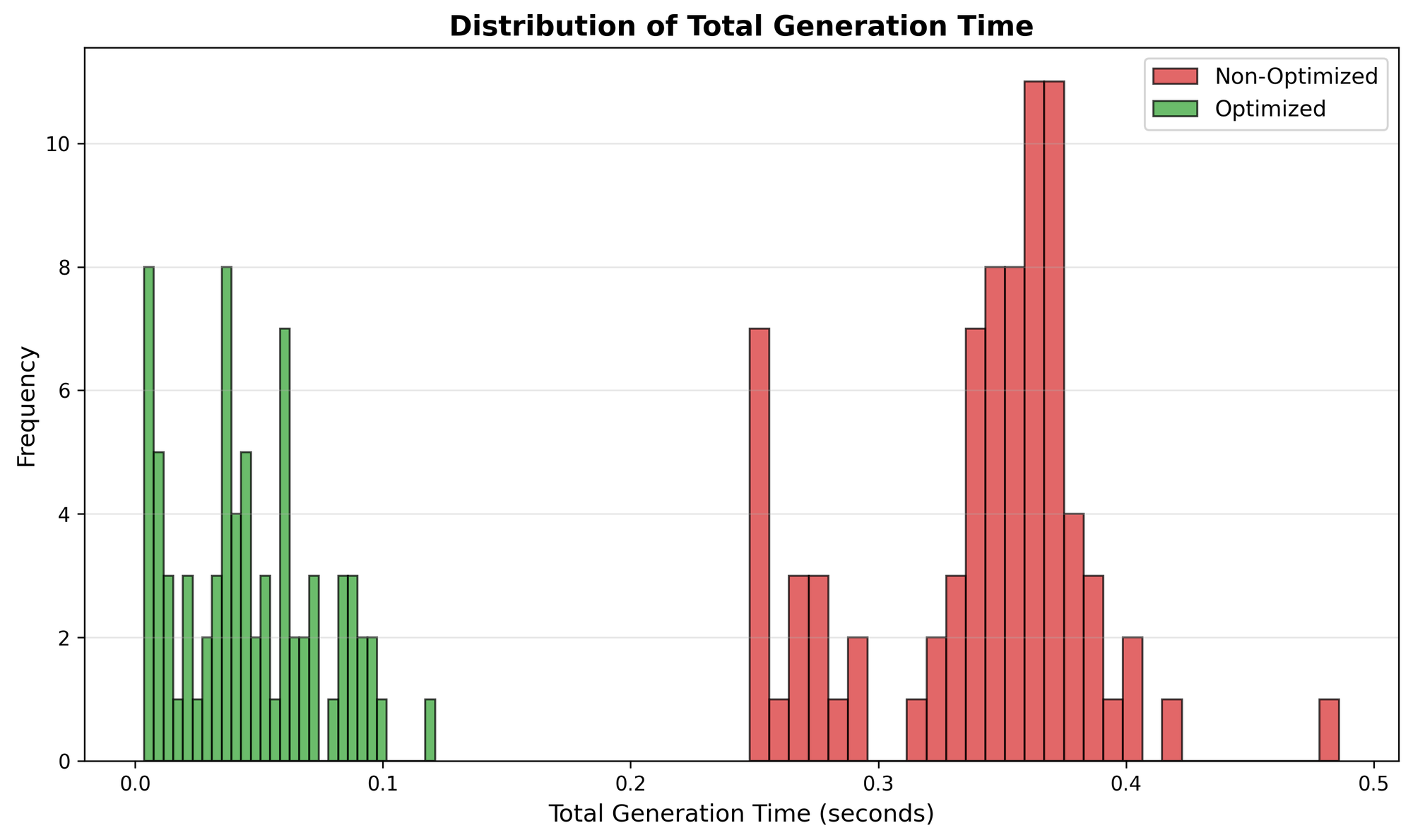
Total generation time: optimized system achieves 3-4x faster generation times, with most operations completing in under 0.1 seconds compared to 0.24-0.48 seconds for non-optimized.
These results validate that the theoretical benefits of KV caching translate directly to practical performance improvements in real implementations.
Conclusion
Optimizing LLM inference is fundamentally a problem of engineering the right data structures. KV caches, prefix sharing, copy-on-write semantics, and intelligent memory management offer practical ways to scale LLM applications without sacrificing performance or accuracy. By understanding and implementing these structures, developers can significantly improve throughput, reduce GPU costs, and build more responsive AI systems.
The techniques discussed here are fully implemented in SheepOp, an open-source transformer implementation that demonstrates these optimizations in practice. Whether you're constructing a research environment, developing a chatbot, or deploying a production inference stack, these data structures provide a foundation for efficient, scalable LLM operations.
With the growing demand for long-context models and high-throughput generation, mastering these optimizations is no longer optional; it is essential.



Comments ()