
LLM understanding
Recently I got an idea during one of the assignments of the master's, what the heck with the LLMs, how those work, how many types are, what is an LLM in fact.
Beginning
The moment started, and then I saw a YouTube video by Andrej Karpathy, one of the key figures in the LLMs boom. He has a video for 2023 explaining all about the famous paper from 2017, "Attention Is All You Need." He explains the paper well in about two hours.
Then I opened a terminal at that moment, and Google - because I needed to search for more papers to understand more - I searched for more information, more and more I was researching, I realized that at the bottom of everything is linear algebra and calculus. So this is the "Aha moment" where the answer to
“When will I ever use math in real life?”
Turns out, it’s not only about attention; it’s all about math.

The real start
I opened the terminal I started to type:
nvim __init__.pyBecause I love Vim - a quick commercial -, after that, I was left with an empty script file, unsure of where to start. Reading papers is not the magic key to unlocking the door to writing code. I review other GitHub projects to understand how to get started.
I made a list of what I need before starting:
- What is an LLM
- How is the LLM structured?
- Why do I need data?
- Why do I need more data?
- How can I generate 6 M dollars?
- What is a token?
Some of the questions are still open, but I'm on the right track to answer them one by one.
What is an LLM
An LLM is defined as a Large Language Model, but what that means is that you have a mathematical model trained based on a language (English, Spanish, Chinese, characters, etc). Anything that is considered language is useful for training a model, and the obvious is that you need a lot of this, which is a large part.
Given that the model is an structure of something you need to know a very big picture of it.

It is all about the data
At this point, it's all about something else. We started with the attention - it seems like the AI had ADHD before 2017 - but why is the data important? And is all the data important?
What I learned this week is that the data is good, but it must be high-quality data, and it needs to be curated before being given to the LLM. That is an exhaustive task for all the models. After the data is curated, it will feed the model to get pre-trained. This is the very beginning part, and it is the longest part so far, until I know. But why is the data important?
The LLMs learned based on how much data is being added; more data means more connections and more pattern recognition by the model.
Tokens!!!
By now, it’s almost a running joke: “Tokenize everything!, tokenize the intokenizable”
A token is a small piece of text — for example:
- “cat” → token X
- “caterpillar” → [x, y, z]
Even though “cat” is inside “caterpillar,” they’re treated as separate tokens. Then, this is the part where self-attention is crucial, and tokenization is taking place.
From a perspective, if you have 150 GB of data, half of which is noise or low-quality text, then you have 75 GB of usable data. For that curated data, you will receive an x M/B of tokens. Those tokens are fed into the model as inputs, which predicts the next token. The difference between the prediction and the actual token is referred to as the "loss." In simple terms:
feed → loss → feedback → repeat
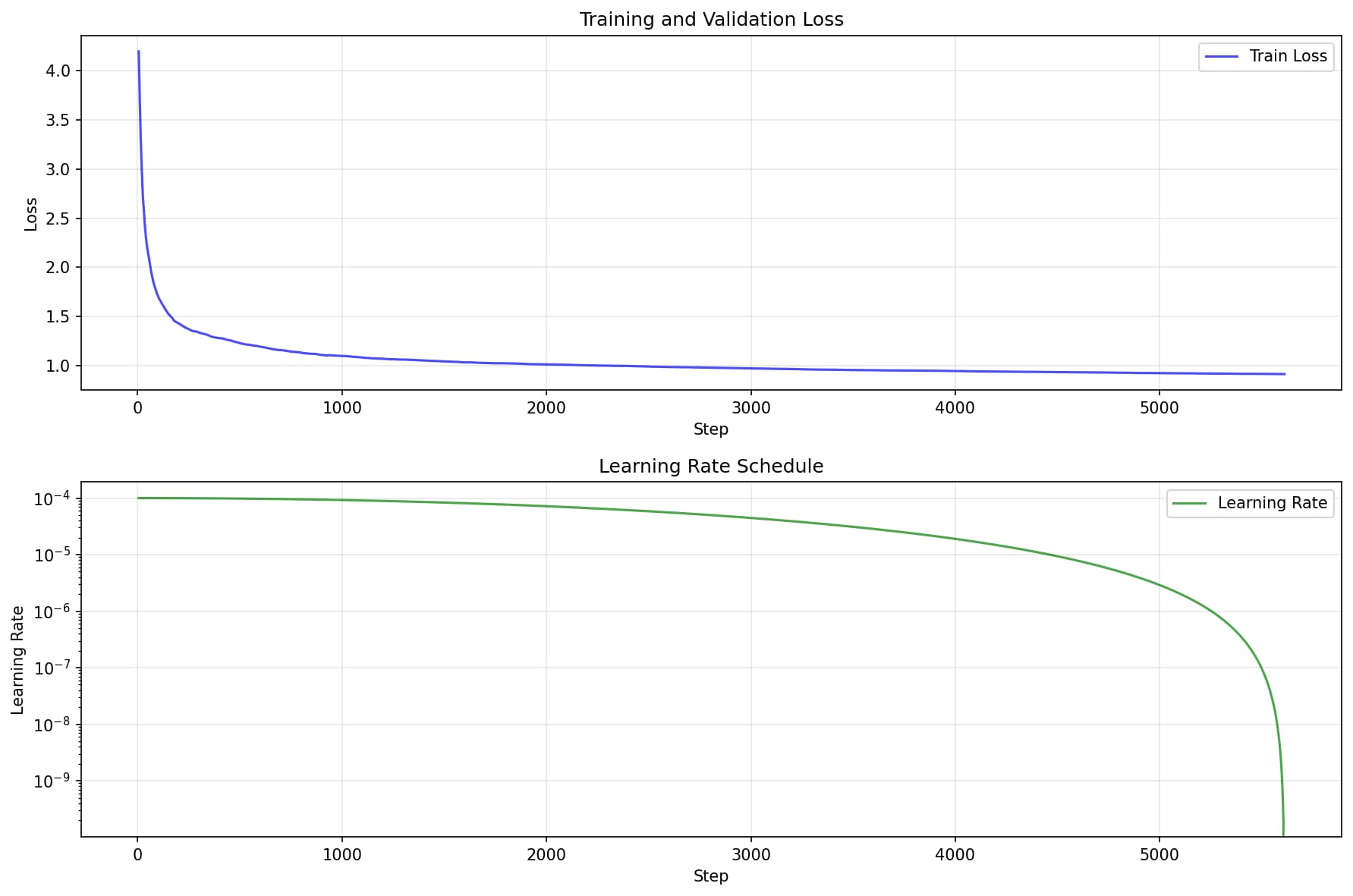
Do that over and over again, and boom — your model is trained, and you get that cute loss curve graph everyone loves.
What is next?
I will continue learning more about what the heck is this magic found 50 years back, and if you want to know more in detail, all my findings, please visit the repository I have created



Comments ()