
Retrieval Optimization for RAG: Data Structures That Make Search Fast and Reliable
In Retrieval-Augmented Generation (RAG) systems, inference efficiency only solves half of the problem. The other half lies in retrieval. Dense retrieval models, vector search indexes, and hybrid scoring mechanisms all rely on data structures whose design significantly impacts performance.
While many developers focus on model architecture and fine-tuning, the retrieval layer often becomes the bottleneck in production RAG systems. In this article, I walk through the data structures and algorithms that make retrieval fast, reliable, and reproducible. Drawing from my work on the LLM RAG Data Structures Optimizer, I explain how hierarchical graph structures, score normalization, and reproducibility techniques come together to build production-grade retrieval systems.
Efficient ANN Search with Reproducible HNSW
Hierarchical Navigable Small Worlds (HNSW) is the backbone of most vector databases. However, HNSW graphs are typically nondeterministic. Node insertion order, random neighbor selection, and parallel processing all produce slightly different results each time.
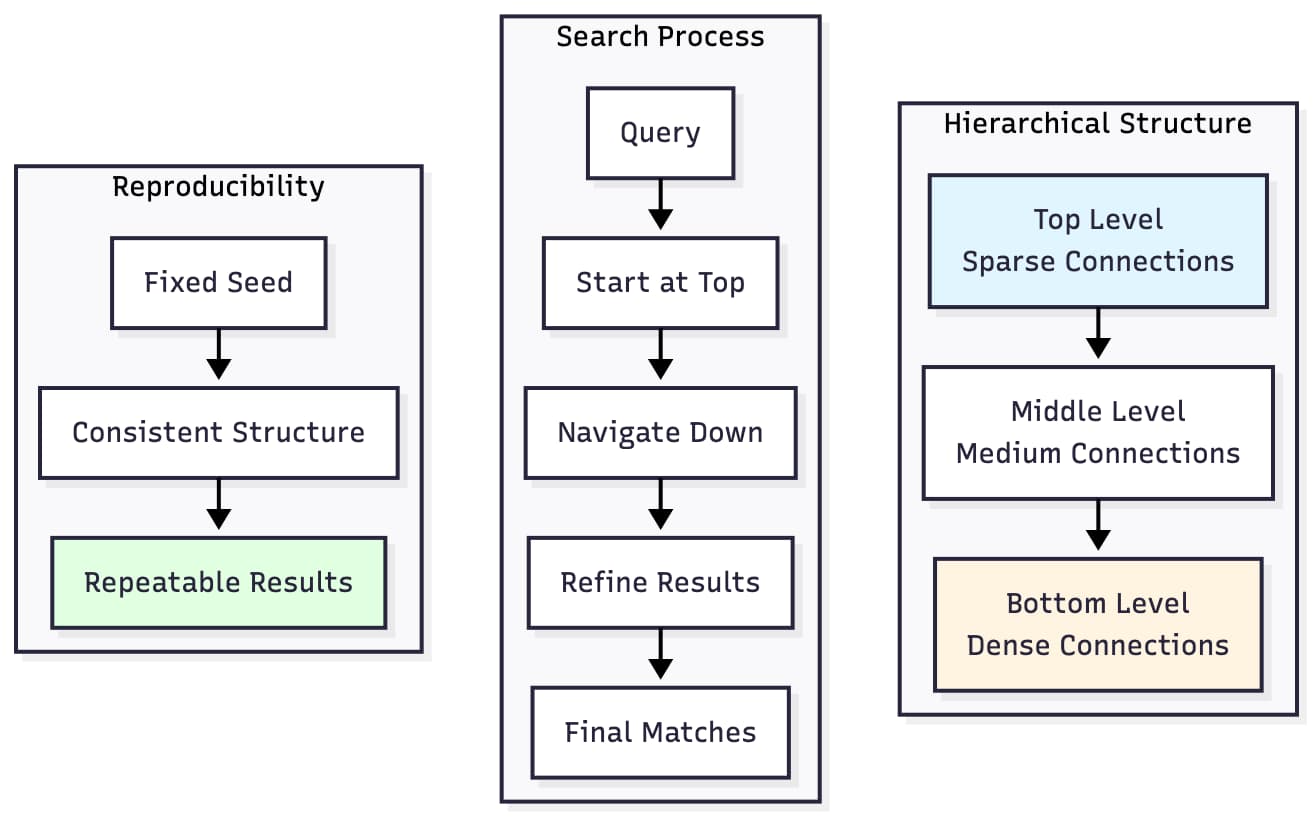
For research and benchmarking, reproducibility is essential. To address this, I explored seeded HNSW construction, allowing controlled graph generation where every run yields the same topology. This enables consistent evaluation of hybrid retrieval strategies and reproducible performance analysis.
The key insight is that HNSW's randomness comes from level assignment during graph construction. By using a seeded random number generator, we can ensure that identical vector insertion orders produce identical graph structures. This is crucial for:
- Debugging retrieval issues in production
- Comparing different retrieval strategies fairly
- Ensuring benchmark results are reproducible
- Validating that optimizations actually improve performance
Hybrid Dense–Sparse Retrieval and Normalized Score Fusion
RAG pipelines increasingly combine dense embeddings with sparse lexical retrieval (e.g., BM25). The challenge is that dense and sparse scores operate on completely different scales. Without normalization, hybrid ranking becomes unreliable.
A technique I adopted, Normalized Additive Score Fusion (NASF), provides a structured method for merging scores. It normalizes each component before combining them, ensuring fair weighting and improved recall. This leads to more stable retrieval performance across domains and query types.
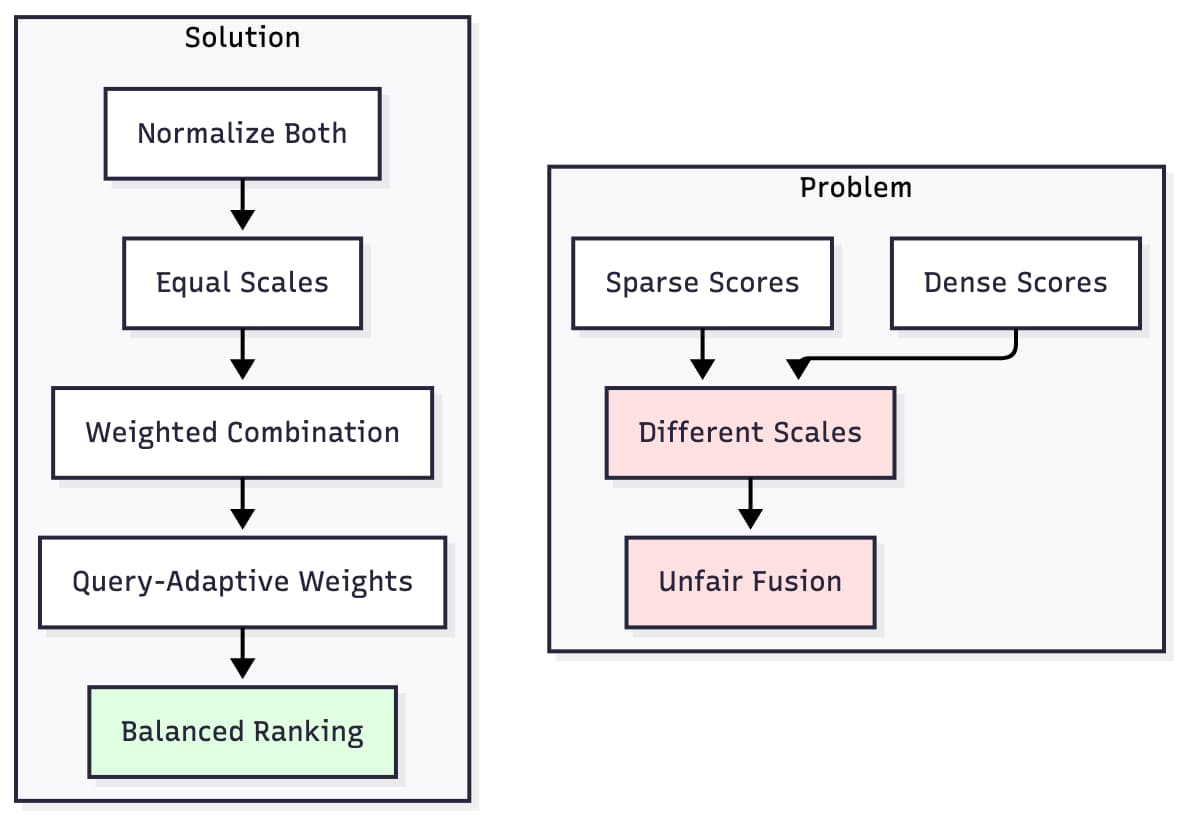
The problem is straightforward: dense similarity scores typically range from 0.0 to 1.0, while sparse BM25 scores can range from 0 to 100 or higher. When you combine them naively, the sparse scores dominate the ranking, making the dense retrieval component irrelevant.
The solution involves three steps:
- Normalization: Scale both score types to the same range (typically 0-1) using min-max normalization
- Weighted Combination: Combine normalized scores with adaptive weights based on query characteristics
- Query Adaptation: Adjust weights dynamically—long queries favor dense retrieval, short queries favor sparse retrieval
This approach ensures that both retrieval methods contribute meaningfully to the final ranking, leading to improved recall and more stable performance across different query types.
Evaluating Performance: Correctness Before Speed
One of the most overlooked aspects of retrieval optimization is validation. Many performance measurements are misleading because they fail to account for warm-up costs, caching artifacts, or non-deterministic behavior. Before benchmarking throughput and latency, the system must first establish correctness.
In my work, I found that validating retrieval behavior required:
- Unit tests comparing retrieval results with and without optimizations
- Strict invariants on score ordering and ranking consistency
- Tests for empty queries, very long queries, and edge cases
- Deterministic seed control for reproducible HNSW structures
- Statistical variance analysis to detect flaky configurations
Only once correctness is reliable does performance analysis make sense. This prevents the common pitfall of "optimizing into a bug," where supposed speedups come from incorrect retrieval behavior rather than real efficiency gains.
Statistical Variance-Aware Benchmarking
For production systems, it's not enough to measure performance once. Real-world systems exhibit variance due to caching, system load, and non-deterministic operations. I implemented a statistical variance-aware benchmarking approach that:
- Runs multiple repetitions of each benchmark
- Calculates coefficient of variation (CV) to detect flaky configurations
- Reports confidence intervals for all metrics
- Flags configurations with high variance for investigation
This methodology ensures that performance claims are backed by statistically sound measurements, not single-run outliers.
Conclusion
Retrieval optimization for RAG systems requires careful attention to data structures and algorithms. Reproducible HNSW construction, normalized score fusion, and statistical validation methodologies provide a foundation for building production-grade retrieval systems that are both fast and reliable.
The techniques discussed here are fully implemented in the LLM RAG Data Structures Optimizer, an open-source library that demonstrates these optimizations in practice. Whether you're building a research prototype or deploying a production RAG stack, these data structures provide the reliability and performance needed for real-world applications.
With the growing importance of RAG systems in production AI applications, mastering these retrieval optimizations is essential for building systems that scale.



Comments ()